
LLM Overdose: Things to Consider Before Pushing to Production

Has your boss shared a tweet with you saying “Hey, look! The problem we’ve been trying to ‘manually’ solve can be easily tackled with this prompt from ChatGPT!, stop wasting your time, use ChatGPT!”?.
Well, this is a guide for when it’s time to have that conversation. Considering you’re a data person in 2023, it likely won’t be long till that happens.
LLMs are wonderful creations, capable of so much more than we currently understand, especially in the conversational AI space. They perform well on common NLP problems such as information extraction, classification, question answering, and more. However, their best NLP use is possibly additive to the current state of data science & engineering, rather than completely replacing it.
Why might in-house solutions of data transformation, cleansing, multiple models, be better than to just use LLM APIs?
That is because when building a solution, we consider multiple factors, notably: accuracy, explainability, latency, cost and privacy. LLM APIs might be accurate, but do not perform well on the rest. Let’s explore how hosted LLMs evaluate against those metrics.
In my time at Drahim (YC22), My team and I built a data enrichment engine that classifies transactions with %97 accuracy. A task like this is especially difficult because the nature of the input data is messy, unstructured and multilingual.
We’ve tackled this problem with an extraction pipeline made up of four machine learning models, pre and post-processing, and efficient use and structure of databases. Let’s see how well LLMs compare in this task.
Accuracy & Task Performance 🎯
First, can LLMs solve the NLP problem we are facing?
Let’s validate that LLMs can solve our NLP problem. I asked ChatGPT to classify a transaction into one of travel, health, or food. Check this example:
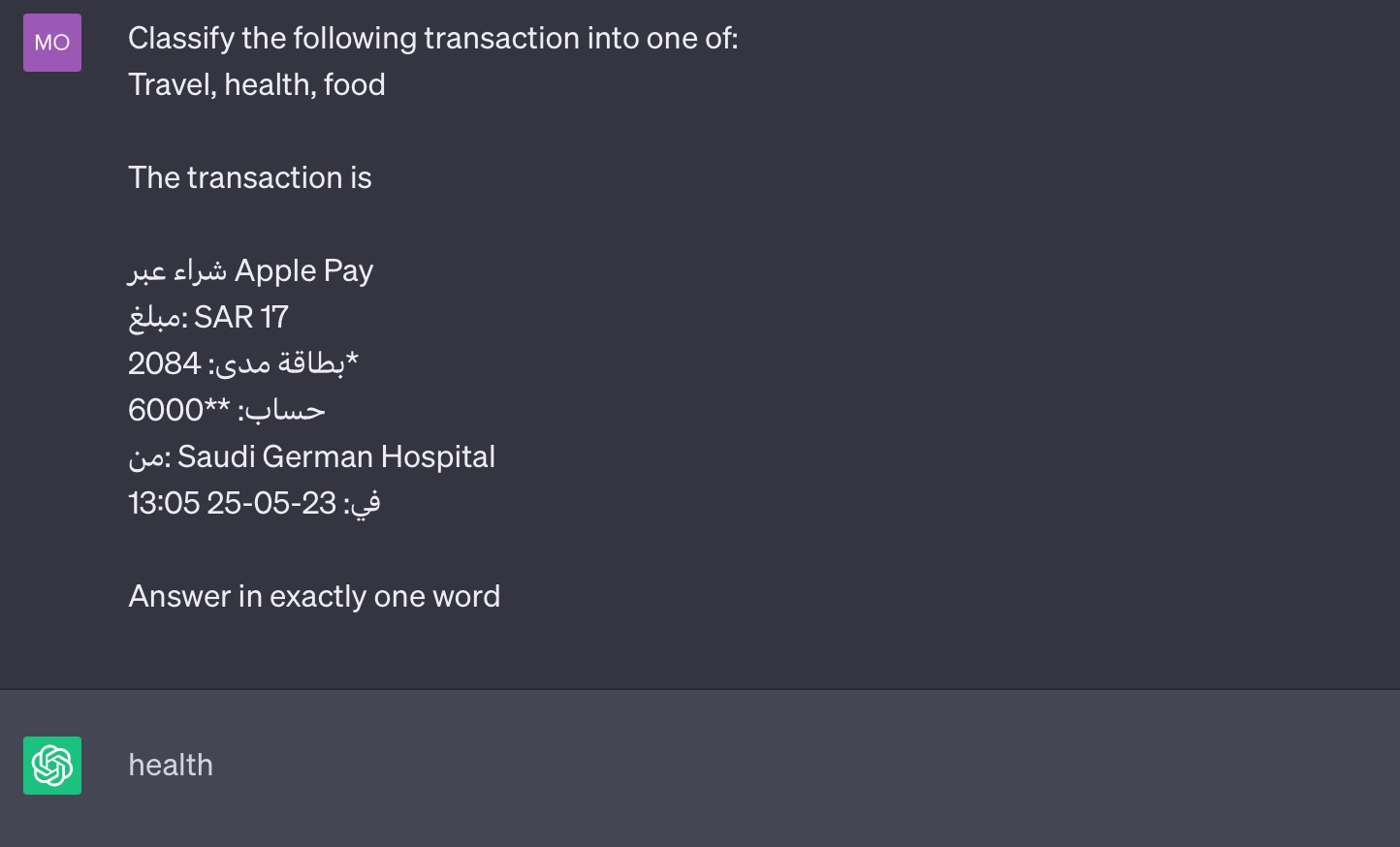
ChatGPT does classify it correctly. However, LLMs may look like they can solve a problem using an example, but that example might be cherry-picked 🍒. Before trying a test set of transactions, we should ask ourselves if this example is representative of the actual data we would encounter. Is it special in some way that allowed the model to predict an answer? and does this example represent the data that I am expecting?
Let’s try another example, missing the ‘hospital’ keyword. This is another example of real life data the model is expected to classify in production (Alnahdi is a popular pharmacy in Saudi):
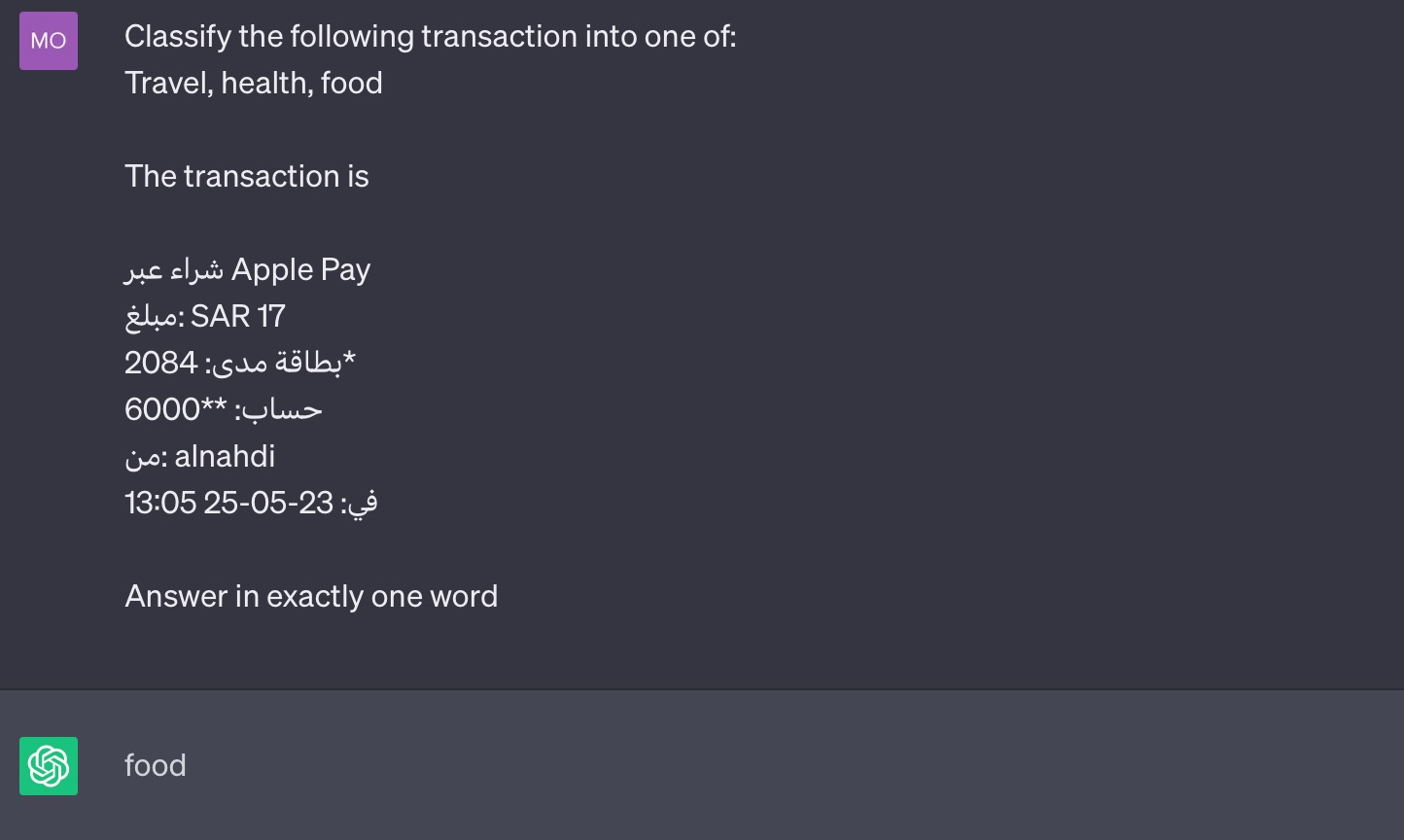
The LLM failed for the second example, understandably (the correct class is health). As I observed working with merchant names in the real world, half of the time the merchant name alone is not indicative (to humans!) of the class of the transaction. That’s a reason transaction classification is a tough problem, tackled by companies that specialize in solving it (e.g. Ntropy).
However, if you try a couple of examples from your data set and the LLM is able to classify them correctly, go forward and ask: Is it able to classify into dynamic classes? Say if you started with the class travel, and then six months later you decided it made more business sense to change to business travel or leisure travel. How robust and predictable would the model answers be?
Also, is the LLM able to classify into your business-specific classes, with their own rules and nuances?
Task Performance Recap
By now we tested a range of examples on the model’s playground, and validated its task performance. If we found it satisfactory, next we test a wider range of examples and evaluate performance with classification metrics (such as F1 score).
Second, are LLMs better than the existing system?
After validating the LLM’s performance, compare it against your current pipeline. If the existing system outperforms the LLM, then we have no reason to replace it. However, if it does solve the problem, and matches or slightly exceeds the results of your in-house work, that’s when the conversation is a bit harder to have.
Say you’ve found that LLMs are a really great fit for your predictive task. Now what?
Explainability 🔍
Explainability is the ability to reason why a model made a specific decision. It’s especially important in high-stake systems; it ensures fair unbiased predictions, as well as allows the ability to debug a failed prediction and calibrate the model accordingly.
LLM APIs rarely, if ever, offer explanations of their predictions, there is no way to reason why a model predicted the answer it gave. This is in contrast to self-hosted models or statistical methods.
Let’s say you’ve found an ML technique to provide some interpretability to your LLM’s predictive task. Then what?
Latency ⏳
A system’s latency is the time it takes to output a response. In this case, the time it takes to classify a transaction.
Latency is an issue whenever you rely on a provider to request & respond over http. Your system’s latency is now dependent on their loads, network, availability, geographical location, etc. You might have outsourced the complexity of the pipeline, but you also introduced an external dependency to your system.
This is a key consideration in any API service, not only hosted LLMs. An advantage of hosting your own models or owning the computation is to own the network. When you’re able to deploy the model and its user (service) on the same premise or cloud, you are able to optimize for latency when needed.
Here is a figure showing OpenAI’s average LLM response time. I added the common acceptable latency of APIs (between 0.5 and 1 second, in pink) to compare.
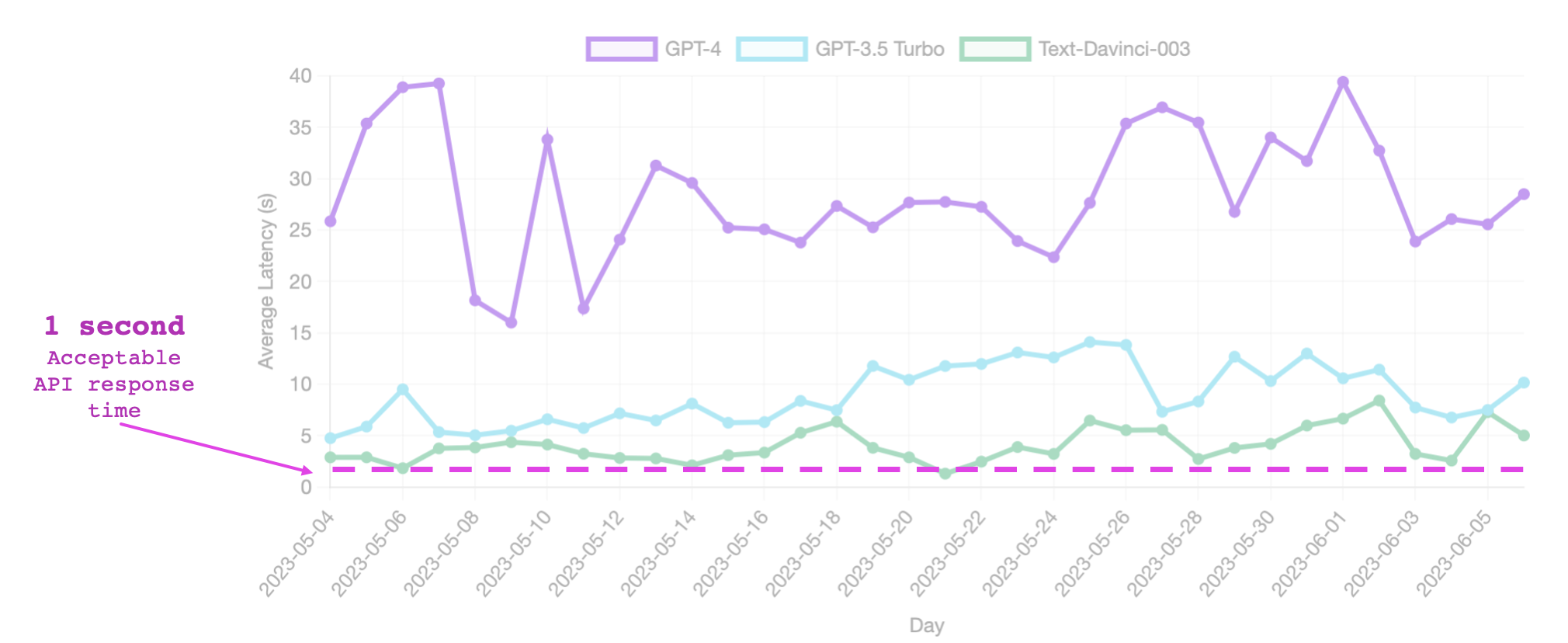
However, say that OpenAI’s API has been hauled and the extra latency is insignificant, then what?
Cost 💸
Since you’re using a hosted service, that comes at a cost, which is a major deterrent from using LLMs beyond a specific threshold of usage volume (10 requests a month are acceptable, a larger number of requests is expensive).
When using LLMs, you are charged per token, which can accumulate quickly, and you might have to restrict the number of tokens (size of input).
Another factor into how costly they can get is mis-use, especially by beginners. In the example I showed above of classifying a transaction, I did not need to include the entire transaction in the prompt. In a regular pipeline, cleansing is normally a step, only the key information relating to the class would be extracted and used for prediction. In this example it’s the merchant’s name.
LLMs cost could sometimes be entirely avoidable when they are an overkill, such as in information extraction problems. In those problems, cleansing scripts and information templates are often part of extracting information (like hardcoded extraction from static templates where the desired text is always in line #2 of the document, for example, or cell B3). Usually, only when those pipelines fail, the system can fallback to more advanced, task-specific models.
This misuse & overuse accumulates cost quickly, also jeopardizes possibly sensitive data.
Privacy 🔒
Finally, hosted LLM API usage has considerations for data privacy. When deciding to use a hosted LLM, sensitive user data needs to be protected and hidden from the provider, factor that into your development time (keep an eye out for my next post covering how to tackle this issue).
Takeaway 🥡
LLMs may be able to solve problems just as well as your existing pipeline does, and using them is simple and straightforward to implement. This may entice people to prematurely to replace existing robust systems with a request to ChatGPT. However, they might not stand as well to other system expectations.
Generative LLMs are powerful, they do make sense in NLP-intense features such as conversations and language generation, but for the rest of NLP problems, it might make sense to invest the time and effort in building your own use-case specific solutions. We did end up using LLM APIs in Drahim, but for a conversational interface over other features.
In Summary, when deciding to use an LLM to solve a problem, consider:
- Accuracy & performance
- Explainability
- Latency
- Cost
- Privacy
These are my two cents, from someone that built in-house models, as well as used hosted models, pertained models, and LLMs in production.
Tweet at me for any questions, corrections, or comments: @Anfal_Alatawi
Photo by Alina Grubnyak on Unsplash